Repo-Aware LoRA Code Generation
Code Assistant LoRA
Code Assistant LoRA is a training and evaluation system for building repo-aware code generation adapters. The goal is not to dump a repository into a model, but to curate task-shaped examples that teach coding conventions, patch behavior, review standards, and verification habits.
The workflow scans source repositories, converts curated examples into train/eval JSONL, trains Gemma-based LoRA adapters on DGX Spark, and evaluates them against code-style gates and specialist reviewer tasks.
The console coordinates a larger coding loop: a primary coding agent proposes a patch, language-specific LoRA reviewers inspect bounded slices of the diff, automated checks provide evidence, and a synthesis step turns reviewer output into actionable revisions.
Gallery
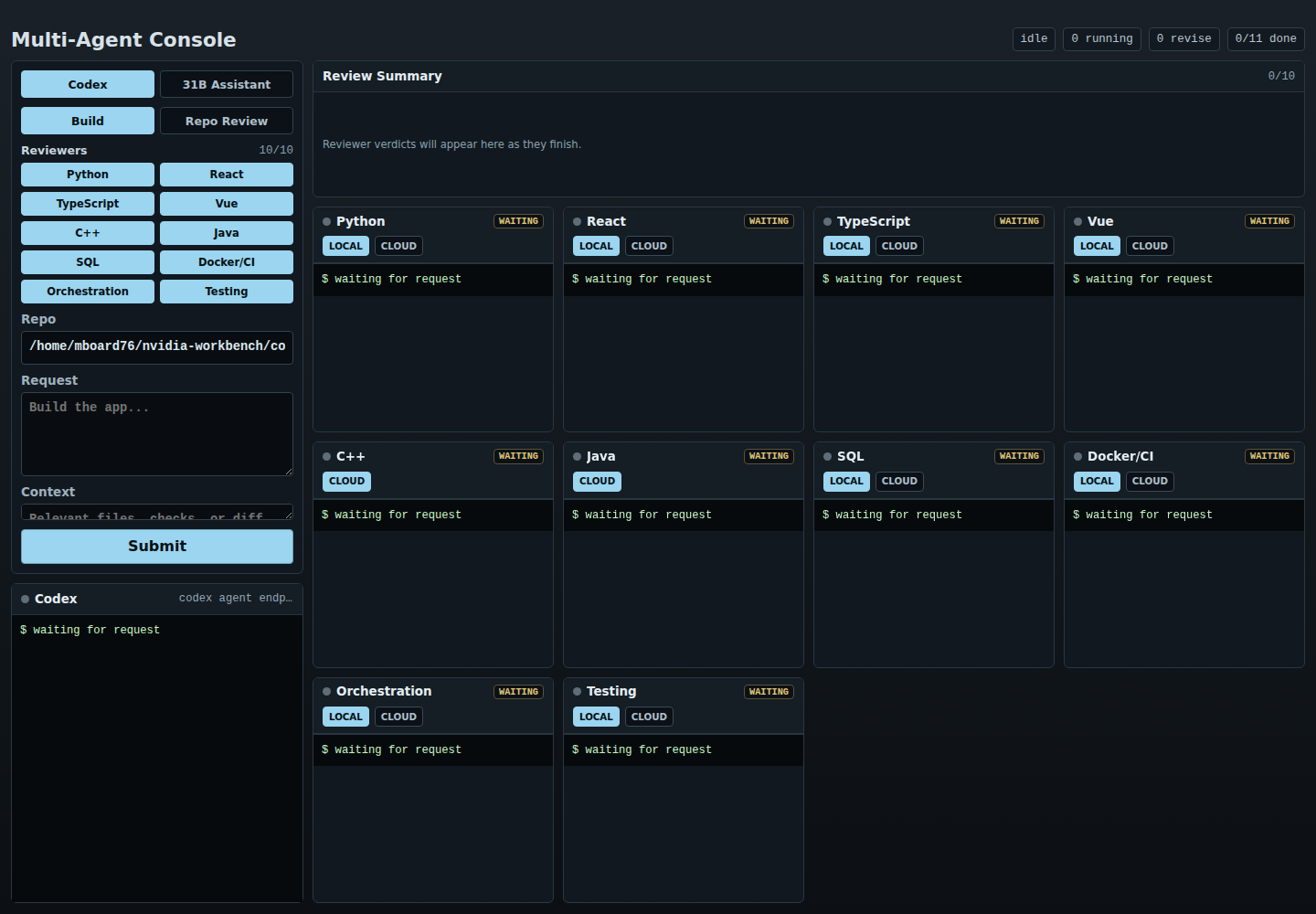
Code Assistant LoRA - Multi-Agent Console

Code Assistant LoRA - Training Outcomes

Code Assistant LoRA - Codex Role Map

Python Reviewer Score Chart

React Reviewer Score Chart

TypeScript Reviewer Score Chart
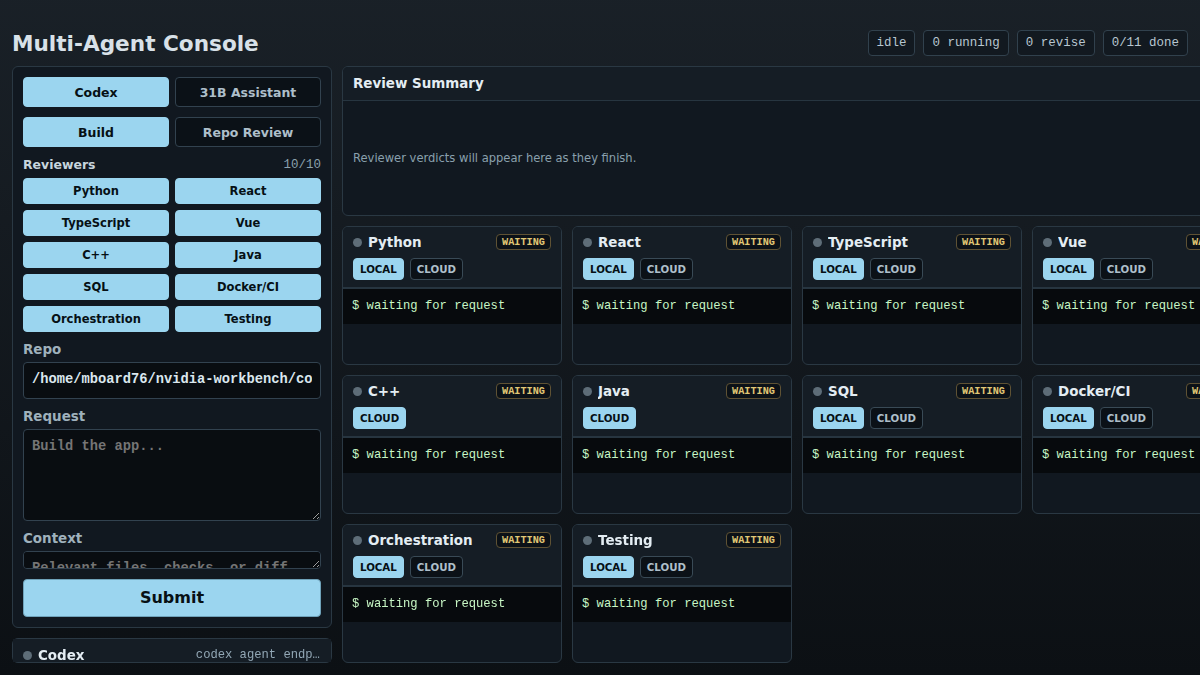
Code Assistant LoRA - Reviewer Grid
Code Assistant LoRA - Mobile View
Case Study
The Problem
General-purpose coding models can write plausible code while missing the details that matter in a real repository: local naming conventions, provider boundaries, test shape, startup config behavior, deployment assumptions, and the difference between a patch that compiles and a patch that belongs.
Design Challenge
Fine-tuning alone is not enough, because repo state changes constantly. The system needed to combine retrieval, tools, tests, curated LoRA behavior, and specialist review without asking one model to carry every language and every convention in one overloaded context window.
My Role
I built this as an agentic software engineering system, not a one-off model experiment. I designed the workflow that lets a primary coding agent propose patches, routes bounded diffs to specialist LoRA reviewers, runs verification gates, and turns reviewer output into actionable revisions. My role covered the full loop: dataset strategy, reviewer contract design, training pipeline, checkpoint evaluation, failure analysis, and promotion decisions. The key engineering challenge was reliability: deciding which parts of code review could be delegated to smaller local adapters, how to constrain their context so they produced useful findings, and how to keep the final patch author responsible for integrating feedback instead of letting multiple agents blindly rewrite code.
Key Design Decisions
The architecture keeps the main 31B code model responsible for patch authorship while smaller LoRA adapters act as fast, opinionated reviewers. Python, React, TypeScript, Vue, SQL, Docker/CI, testing, and orchestration reviewers receive narrow context and return findings, missing checks, and suggested fixes. The general model integrates the feedback and resolves conflicts.
Outcome
The project produced a repeatable pipeline for curated SFT data, LoRA training, checkpoint evaluation, score tracking, and multi-agent patch review. It turns local convention learning into a measurable workflow instead of a vague prompt-engineering exercise.
System Architecture
Training Results
The most important result was not lower loss by itself; it was structured, role-specific behavior that survived held-out reviewer scenarios and behavior gates. The base E4B reviewer repeatedly failed the JSON contract, while LoRA adapters learned valid approve/revise/block outputs quickly.
Current 31B candidate
25/26
Run 016 checkpoint 360 across the repaired behavior gate.
Main gate
8/8
Run 016 preserved the original code-style eval.
Gate 2
7/8
Only remaining miss was explicit service-role wording.
Gate 3
10/10
Integrated behavior and Markdown-context cases passed.
Reviewer contract
0% -> 100%
Base E4B produced invalid JSON; adapters produced structured reviewer output.
Adapter placement
820 / 0
31B LoRA tensors landed under language_model, not vision/audio towers.
Python reviewer
24/24 from checkpoint 20 onward
React reviewer
24/24 from checkpoint 20 onward
TypeScript reviewer
24/24 from checkpoint 40 onward
Vue reviewer v1
15/18 before augmented data
Vue augmented
18/18 after augmented boundary data
SQL reviewer
24/24 across checkpoints
Docker/CI reviewer
24/24 across checkpoints
Testing reviewer
24/24 across checkpoints
Orchestration reviewer
24/24 across checkpoints
Codex Role Setup
Codex or 31B Gemma
Primary Patch Author
Owns the implementation, applies revisions, and resolves conflicting reviewer feedback instead of letting specialists rewrite the whole task.
Python, React, TypeScript, Vue, SQL, Docker/CI, Testing, Orchestration
Local LoRA Reviewers
Receive the task, bounded diff, retrieved context, and check output. Return structured JSON with verdict, findings, missing checks, and suggested fix.
Frontend, accessibility, testing, deployment, C++, Java
Cloud Codex Reviewers
Used for high-accuracy review when a domain needed broader reasoning than the local adapter or when no local LoRA existed yet.
Final reviewer
Codex Synthesis
Deduplicates reviewer findings, separates blockers from nits, and hands the primary author a short actionable revision plan.
Technical Highlights
Curated SFT Pipeline
Scans repositories for context, converts hand-curated task examples into train/eval JSONL, and avoids whole-repo dumps that teach weak or stale behavior.
DGX Spark LoRA Training
Uses Spark-specific setup for Gemma-based adapters with PyTorch, Transformers, PEFT, Accelerate, and optional QLoRA paths.
Specialist Reviewer Adapters
Routes diffs to language and responsibility specialists for Python, React, TypeScript, Vue, SQL, Docker/CI, testing, and orchestration review.
Evaluation Gates
Tracks checkpoint quality with code-style gates, reviewer evals, smoke checks, and score charts so model changes can be compared instead of guessed.
Agent-Assisted Build Process
Uses Codex as part of the development loop while keeping human ownership over requirements, architecture, generated-code review, eval design, and final promotion decisions.